tanstaafl.dev
파이썬 40줄로 Wordle을 풀어보자
숫자 야구의 글자 버전인 Wordle이 요즘 대인기다. 숫자 야구랑 똑같아 보이지만 실제 존재하는 단어만 넣을 수 있다는 점 덕분에 해보면 은근히 재미있다. 허나 나의 몹쓸 개발자 근성 덕분에 이걸 하면서도 "이거 프로그램으로 짜면 바로 풀텐데.." 생각이 계속 들었다.. 그러니 짜 보도록 하자.
우선 단어 목록부터 가져오자. 리눅스나 맥 시스템에는 /usr/share/dict/words에서 영단어 목록을 쉽게 얻을 수 있다. 파이썬의 리스트 축약 문법을 사용하면 간단하다.
# 영문자로만 구성된 5글자 단어만 대문자로 바꿔 모은다.
words = [w.upper() # (1)
for w in open('/usr/share/dict/words').read().splitlines() # (2)
if w.isalpha() and len(w) == 5 # (3)
]
upper()는 문자열을 대문자로 바꿔 준다.read().splitlines()를 통해 각 문자열 뒤에 따라오는 개행 문자(\r)를 지워 준다.- 이 부분은 숫자나 문장 부호가 들어가지 않고 (
isalpha()) 5글자인 (len(w) == 5) 단어만을 걸러낸다.
Wordle의 가장 중요한 부분은 정답과 추측이 주어졌을 때 어느 글자가 맞고 어느 글자는 위치가 틀렸는지 알려주는 로직이다. Wordle은 우선 위치까지 맞춘 글자들을 전부 녹색으로 표시하고, 정답의 나머지 글자들 중 맞았는데 위치만 틀린 글자들을 노란색으로 표시해 준다. 이 때 어떤 글자 X가 정답에 N번 출현하면, 추측에 나온 X는 N개까지 노란색으로 표시되고, 나머지는 회색으로 표시된다.
- 예 1: 정답이
BANAL인데BIBLE라고 추측한 경우. 이 때 첫 글자인B는 이미 녹색이 되어서 세 번째 글자인B는 회색으로 출력된다. - 예 2: 정답이
BANAL인데ALLOY라고 추측한 경우.L는 정답에 한 번 나오는데 우리의 추측에는 두 번 들어있다. 이 때는 첫 번째로 찍은L만 노란색이고, 두 번째L은 회색으로 표시된다.
먼저 정답이 answer, 추측이 guess 문자열에 들어 있을 때 노란색이 될 수 있는 글자들의 후보를 찾아보자.
# 정답에서 노란색 후보가 될 수 있는 글씨들의 목록을 찾자.
misses = [a # (3)
for g, a in zip(guess, answer) # (1)
if g != a # (2)
]
zip(guess, answer)는 두 문자열에서 한 글자씩 떼내어 쌍을 만들어 준다.g,a는 각각guess,answer의 첫 글자로 시작하고, 두 번째 반복에서는 두 번째 글자가 된다.g == a인 경우 초록색으로 표시되니까 제외해야 한다.a, 다시 말해 정답에 포함된 글자만을 모은다.
그리고 나면 추측의 각 문자를 보며 어떤 색이 될지를 계산할 수 있다.
color = []
for g, a in zip(guess, answer):
if g == a:
color.append('G')
elif g in misses: # (1)
misses.remove(g) # (2)
color.append('Y')
else:
color.append('.')
- 여기에서
misses는 정답 중 녹색이 아닌 글자들을 담는 리스트다. 우리가 추측한 글자g가 여기 있다는 것은 위치만 틀렸다는 것이기 때문에, 이 글자는 노란색이 된다. - 한 글자가 추측에 여러 번 들어가는 경우, 정답에 들어 있는 개수만큼만 노란색이 되므로 리스트에서 이미 사용한 글자는 지워준다. 파이썬 리스트의
remove는 글자가 여러 개 있을 경우 하나만 지워 준다.
이것을 모아 다음과 같은 함수를 작성할 수 있다.
def check(guess, answer):
misses = [a for g, a in zip(guess, answer) if g != a]
color = []
for g, a in zip(guess, answer):
if g != a and g in misses:
misses.remove(g)
color.append('Y') # 노란색 Y
elif g == a:
color.append('G') # 녹색 G
else:
color.append('.') # 회색은 .로 표시
return ''.join(color)
간단 테스트:
>>> wordle.check('BIBLE', 'BANAL')
'G..Y.'
>>> wordle.check('ALLOY', 'BANAL')
'YY...'
다음으로 어떤 단어를 찍을지 정하는 첫 단계는 우리가 아는 단어들 중 정답일 가능성이 있는 것들만 골라내는 것이다. 지금까지 플레이한 기록이 리스트 history에 들어 있다고 하자. 이 리스트의 각 원소는 (guess, result)이다. guess는 우리가 찍은 단어, result는 이 때 얻은 각 글자의 색깔이다. 예를 들어
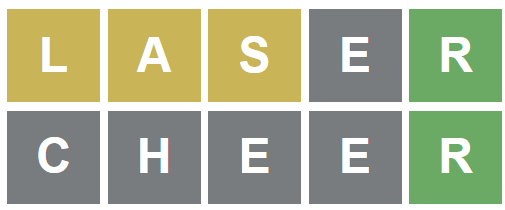
이 플레이 기록은
[('LASER', 'YYY.G'),
('CHEER', '....G')]
로 저장하는 식이다.
어떤 단어가 정답일 가능성이 있는지 알려면, 이것이 정답이라고 가정했을 때 history와 일치하는지 보면 된다. 리스트 축약을 이용하면 한 줄에 짤 수 있다. (80글자가 넘어가지만..)
candidates = [w for w in words if all(check(guess, w) == result for guess, result in history)]
check(guess, w) == result는w가 정답일 때,guess라고 추측해서result라는 결과를 얻었을지 확인한다.all()은 입력으로 주어진 반복자(iterator)의 모든 원소가 참인 경우 참을, 아닌 경우 거짓을 반환한다. 여기서는history의 모든(guess, result)쌍에 대해w가 정답일 가능성이 있으면 참을 반환하게 된다.
이제 답일 가능성이 있는 단어들을 다 알았다. 그러나 그렇다고 해서 그 중에서 가장 흔한 단어를 찍거나 해서는 6번의 기회 안에 답을 알아내지 못할 수 있다. 6번 안에 문제를 풀려면 한 번 추측을 할 때마다 정답 후보들(위의 candidates)의 개수를 최대한 줄여야 한다.
어떻게 하면 매 번 추측마다 정답 후보들의 개수를 최대한 줄일 수 있을까? 정답 후보가 100개 있다고 하자. 어떤 단어 A가 좋은 추측인지를 확인해 보려면 각 후보마다 A가 어떤 결과를 얻을지를 각각 계산해 본다. 예를 들어 다음과 같은 결과를 얻었다고 하자.
* 후보 1이 정답일 경우: G..G.
* 후보 2이 정답일 경우: G..G.
* 후보 3이 정답일 경우: G..G.
* 후보 4가 정답일 경우: G..G.
.... (모두 같음)
* 후보 99가 정답일 경우: G..G.
* 후보 100이 정답일 경우: YYGGG
반면 단어 B를 추측했을 경우 어떤 결과를 얻을지 계산해 보니 다음과 같았다고 가정하자.
* 후보 1이 정답일 경우: G..G.
.... (모두 같음)
* 후보 60이 정답일 경우: G..G.
* 후보 61이 정답일 경우: YYGGG
.... (모두 같음)
* 후보 100이 정답일 경우: YYGGG
A와 B 중 어느 쪽을 찍는 게 더 유리할까? A를 찍어서 운좋게 YYGGG를 얻으면 다음에 바로 답을 맞출 수 있다. 하지만 G..G.를 얻을 경우 후보의 개수가 100에서 99로 한 개 줄어들 뿐이다. 반면 B를 찍으면 운이 좋으면 정답 후보의 개수를 40개로 줄일 수 있고, 최악의 경우에도 정답 후보의 개수를 60개로 줄일 수 있다. 운이 나쁘더라도 6번 안에 정답을 맞출 수 있는 확률은 B가 더 높다고 볼 수 있다.
이 직관을 이용해 어떤 단어 G가 얼마나 좋은 추측인지에 대한 기준을 다음과 같이 세워 보자.
- 각 정답 후보에 대해
G가 어떤 결과를 얻을지를 계산한다. - 후보들을 이 결과별로 분류해 그룹으로 나눈다.
- 제일 포함된 후보가 많은 그룹의 크기를 구한다.
- 이것이 적으면 적을 수록 좋은 추측이다.
어떤 단어 guess가 주어질 때, candidates의 모든 후보에 대해 그 결과를 다음과 같이 계산할 수 있다.
[check(guess, cand) for cand in candidates]
파이썬 표준 라이브러리의 collections.Counter에 이 결과를 넣으면 각 결과가 몇 번이나 나오는지 세어준다.
Counter(check(guess, cand) for cand in candidates)
이 중 최악의 경우 (같은 결과를 갖는 후보들이 제일 많은 경우) 를 찾기 위해서는 most_common() 함수를 사용하면 된다. 이들을 결합하면 다음과 같은 형태의 함수가 된다.
def largest_group_size(guess):
partition = Counter(check(guess, cand) for cand in candidates)
[(_, freq)] = partition.most_common(1)
return freq
이제 모든 단어 중 이 기준을 최적화하는 단어를 찾자. min()을 쓰면 간단하다.
min(words, key=largest_group_size)
- 파이썬의
min(),sorted()등의 함수들은key인자에 주어진 원소의 우선순위를 계산하는 함수를 넘길 수 있도록 되어 있다. 그러면 주어진 목록의 원소를 비교하는 대신 각각의 우선순위를 계산하고 이들의 비교를 통해 최소 원소를 찾거나 정렬해준다. min()의 첫 번째 인자가candidates가 아니라words(모든 단어) 이라는 점에 유의. 항상 정답 후보만 찍는 것이 제일 좋은 것은 아니다.
결합하면 이런 함수가 된다.
def best_guess(history):
# 정답 후보 목록 구하기
candidates = [w for w in words
if all(check(guess, w) == result for guess, result in history)]
# 정답 후보가 하나인 경우 바로 반환
if len(candidates) == 1: return candidates[0]
# guess를 찍었는데 최악의 경우에 정답 후보 개수는?
def largest_group_size(guess):
partition = Counter(check(guess, cand) for cand in candidates)
[(_, freq)] = partition.most_common(1)
return freq
# 최악의 경우에도 정답 후보 크기가 가장 많이 줄어드는 단어를 구한다
return min(words, key=largest_group_size)
이제 이들을 모두 모아보면 다음과 같은 40줄 코드가 된다.
from collections import Counter
words = set(w.upper() for w in open('/usr/share/dict/words').read().splitlines() if w.isalpha() and len(w) == 5)
def check(guess, answer):
misses = [a for g, a in zip(guess, answer) if g != a]
color = []
for g, a in zip(guess, answer):
if g != a and g in misses:
misses.remove(g)
color.append('Y') # 노란색 Y
elif g == a:
color.append('G') # 녹색 G
else:
color.append('.') # 회색은 .로 표시
return ''.join(color)
def best_guess(history):
if len(history) == 0: return ['OATES', 'AIRES', 'ARIES', 'NEARS', 'AROSE', 'SNARE', 'SANER', 'REALS', 'LANES', 'SADIE']
candidates = [w for w in words if all(check(guess, w) == result for guess, result in history)]
if len(candidates) <= 1: return candidates
def largest_group_size(guess):
partition = Counter(check(guess, cand) for cand in candidates)
[(_, freq)] = partition.most_common(1)
return freq
return sorted(words, key=largest_group_size)[:10]
if __name__ == '__main__':
history = []
while True:
guess = best_guess(history)
print('TRY ONE OF:', ', '.join(guess))
guess = input('WHAT WAS YOUR GUESS: ')
result = input('WHAT WAS THE RESULT: ')
if result == 'GGGGG': break
history.append((guess, result))
과거 Wordle을 몇 개 풀어 보고 나서 몇 가지 고친 점이 있다.
best_guess()는 제일 좋은 추측 하나 대신 상위 10개를 반환한다.words에 들어 있는 단어들 중 Wordle이 인식하지 않는 단어가 많아서, 그런 경우 그보다 덜 좋은 추측을 사용해야 하기 때문이다.history에 아무 원소도 없는 경우best_guess()는 꽤 느리다. (내 컴퓨터에서는 1분 정도 걸린다.) 다행히 이 경우의 제일 좋은 추측들은 항상 똑같으니까 하드코딩해 뒀다.
테스트로 Wordle 200을 풀어 보았다.
$ python wordle.py
TRY ONE OF: OATES, AIRES, ARIES, NEARS, AROSE, SNARE, SANER, REALS, LANES, SADIE
WHAT WAS YOUR GUESS: NEARS
WHAT WAS THE RESULT: .Y.Y.
TRY ONE OF: PRIOR, TIMOR, TUDOR, CHOIR, OILED, RIGOR, OSIER, OLDIE, VIGOR, DOGIE
WHAT WAS YOUR GUESS: PRIOR
WHAT WAS THE RESULT: ..Y.G
TRY ONE OF: VELDT, DOLTS, DELTA, ADULT, DWELT, TILED, TIDAL, DEALT, TILDE, DRAFT
WHAT WAS YOUR GUESS: ADULT
WHAT WAS THE RESULT: ....Y
TRY ONE OF: GAMIN, BIMBO, MIDGE, GAMEY, MAGIC, MOBIL, GIMME, GAMES, MIGHT, LIMBS
WHAT WAS YOUR GUESS: MAGIC
WHAT WAS THE RESULT: ..GY.
TRY ONE OF: TIGER
WHAT WAS YOUR GUESS: TIGER
WHAT WAS THE RESULT: GGGGG
짠. 그래도 프로그램으로 풀고 SNS에 올려 자랑하진 말자.